Resume Wrapped

Resume Wrapped
TL;DR: head to https://resume.trentbowden.dev/ and have a play around
A shallow dive into the PDF file structure, with a fun ending.
Yearly, all your favourite companies stress test their Postgres instances by running statistic summary queries to provide you an insight to how you live.
Spotify shows your favourite songs, Banking apps explore spending trends, but what about your work life?

For years, we've been carrying around a PDF with all the information about our work-life neatly summarised, why not use an LLM to deduce quirky things from it?
Let alone the possibility of sassy comments.

The first step towards a fun & sassy resume wrapped infographic is nailing the resume parsing. To understand how hard this step is, we must first step into the world of a PDF’s structure.
PDF structure fly-by
I’m learning as you’re learning. Already knew this?, you get a point for every note on what I get wrong.
The structure of a PDF feels like a read-only standard, not to be reverse engineered.
Super handy for printers. Each matryoshka in the PDF structure holds information helpful to each stage of the printing process, and exact locations of content described with Quads (4-sided shape) in a User Space coordinate system, so there's (less) worry about sizing differences across devices.
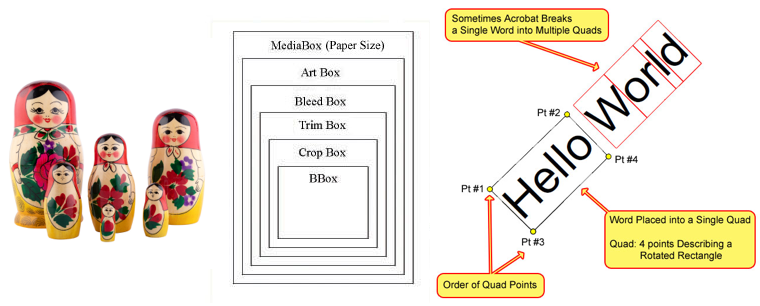
Super not handy for reverse engineering:
- While it is possible* to store text as strings, text is likely stored as individually placed characters (or groupings of substrings). It’s even common for text to be rendered with draw paths like a canvas. It’s entirely up to the software generating the document.
- Changes to an existing PDF are appended to the end of the file, meaning you may need to render the entire file just to view the front page.
While we’re poking holes, it’s also worth noting some fun security flaws.
Fonts with hinting (changing how the font displays for legibility at different resolutions) use embedded executable code, which (until Windows 10 Anniversary update) was executed in Kernel mode on Windows, meaning with the right host environment, you can execute shell commands from a PDF.

I'm guessing the frictionless consistency of appearance was a big drawcard in a time (1993) where replacing physical paper with digital documents was ripe. Alternatives like DjVu, PostScript, EPUB or OpenXML all have their strengths, but don't hit the same mark for creation and consumption.
With all this in mind, let’s get on with it.
Attempting to parse a simple resume
Failed option #1: Using Open Resume
I searched packages high and low on the first page of google, to get Open Resume, what looks like a reputable resume creator & parser.
Created by Xitang Zhao and designed by Zhigang Wen, they provide a pretty neat algorithm breakdown, describing:
- Using Mozilla’s open-source pdf.js to retrieve and sort all text items & metadata (for each text item, ask: is it bold? Does it start on a new line? etc)
- Connecting adjacent text items into one if their distance is smaller than character width, grouping lines into sections and scoring sections by likelyhood of being a child for each resume attribute
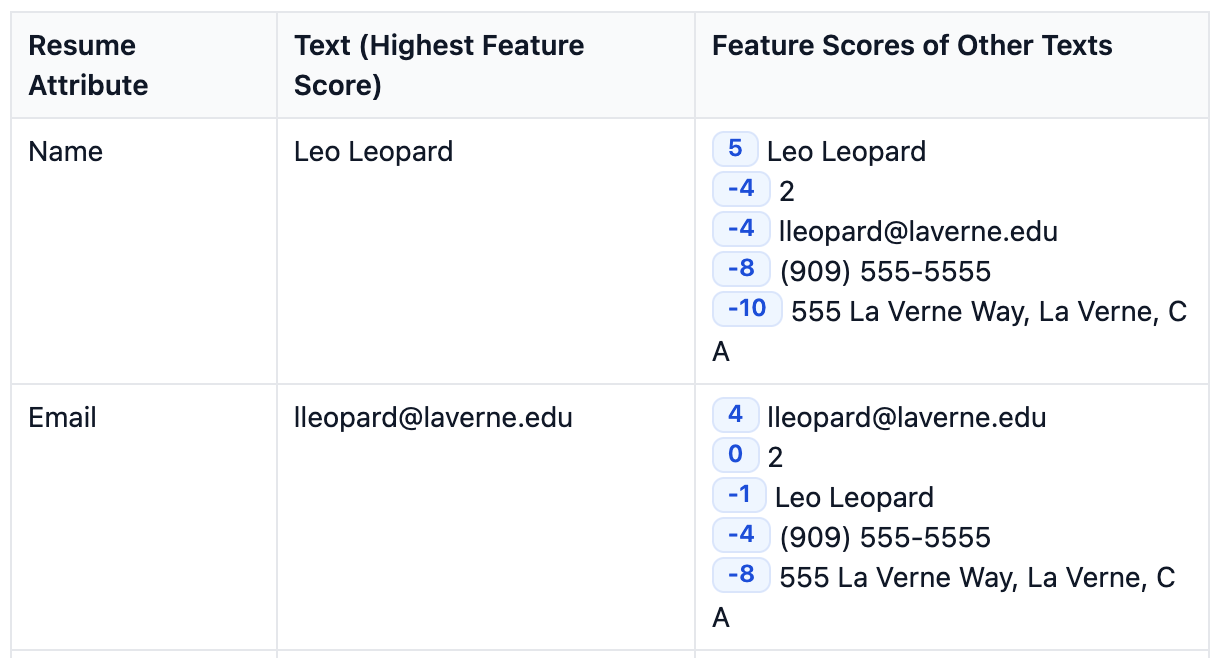
And finally, matching a set of Regex functions for core resume features.
Note that this falls down quickly when a locale is not configurable. Phone number structures, dates, location formats are hard to universally nail down.
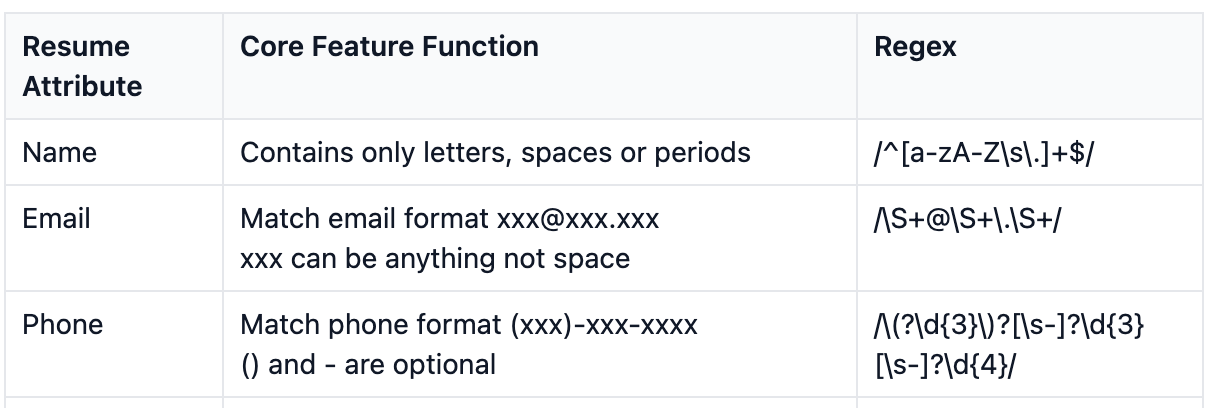
Despite this excellent algorithm breakdown, if a resume doesn’t conform to the expected/inflexible rules, the job deteriorates quite fast. So we try something else.
Parse text & use ChatGPT
While we could use OpenAI Vision, it’s cheaper to hit their servers with text than it is with an image or document. We learned from the Open Resume approach that text can be scraped, and I’m confident (at this point in time) that ChatGPT can clean up any mess of dismembered tokens for us.
First, we want a package to read PDF files (ignoring scanned documents), luckily, benchmarking has already been done for me here, describing quality and speed over a range of documents.
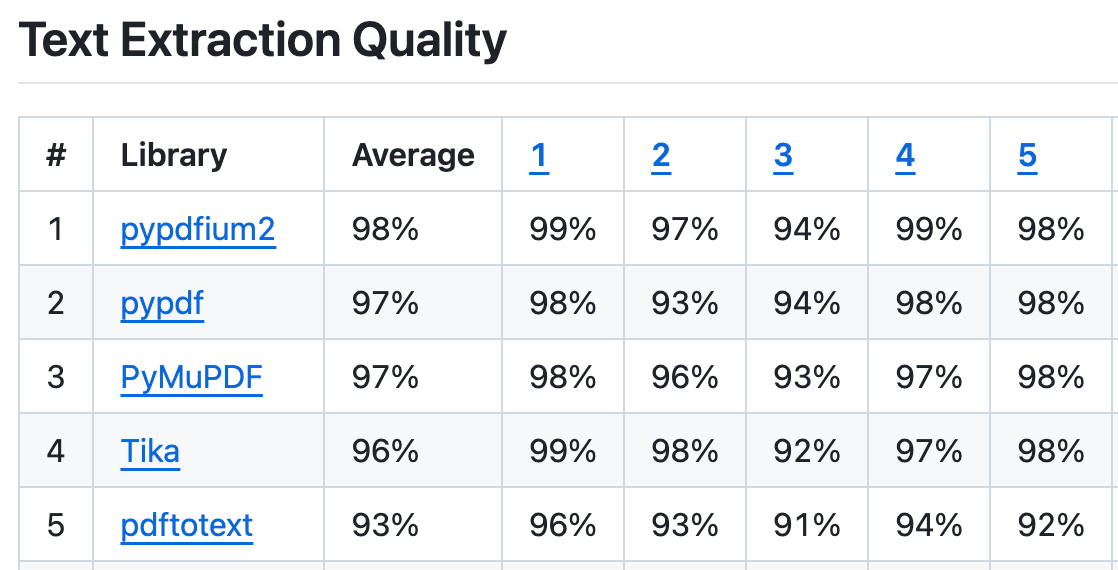
I’ve heard more about pypdf, and the docs seem easier to digest for a side-project. Let’s go with that.
With 5 lines of code,
from pypdf import PdfReader
reader = PdfReader("example.pdf")
number_of_pages = len(reader.pages)
page = reader.pages[0]
text = page.extract_text()
print(text)We are given enough text for ChatGPT to parse everything correctly. This highlights the benefit of an LLM when you've got unorganised shrapnel to parse.
Serving content
What is the most lightweight way to allow uploads, and serve a page?
Staying away from overengineering (React + API backend), we must understand the most important part of Spotify wrapped is not the slideshow, but the shareable infographic.
That’s our MVP.
The plan

Provide a colourful bento box of fake statistics and sassy information, centered around what can be deduced from the given resume.
From here, we'll:
- Sketch up the summary page, recreate in html/css.
- Parse an uploaded file, hit ChatGPT for some fun responses.
Sketching the summary page
Starting with a colour pallette that looks like Spotify,

The font that Spotify used to use,

And expecting 4 infographic spaces, we come up with a quick sketch:

Putting it into action
This is a real basic project. Translated the sketch into html/css, served using Django run by Gunicorn on an Nginx server.
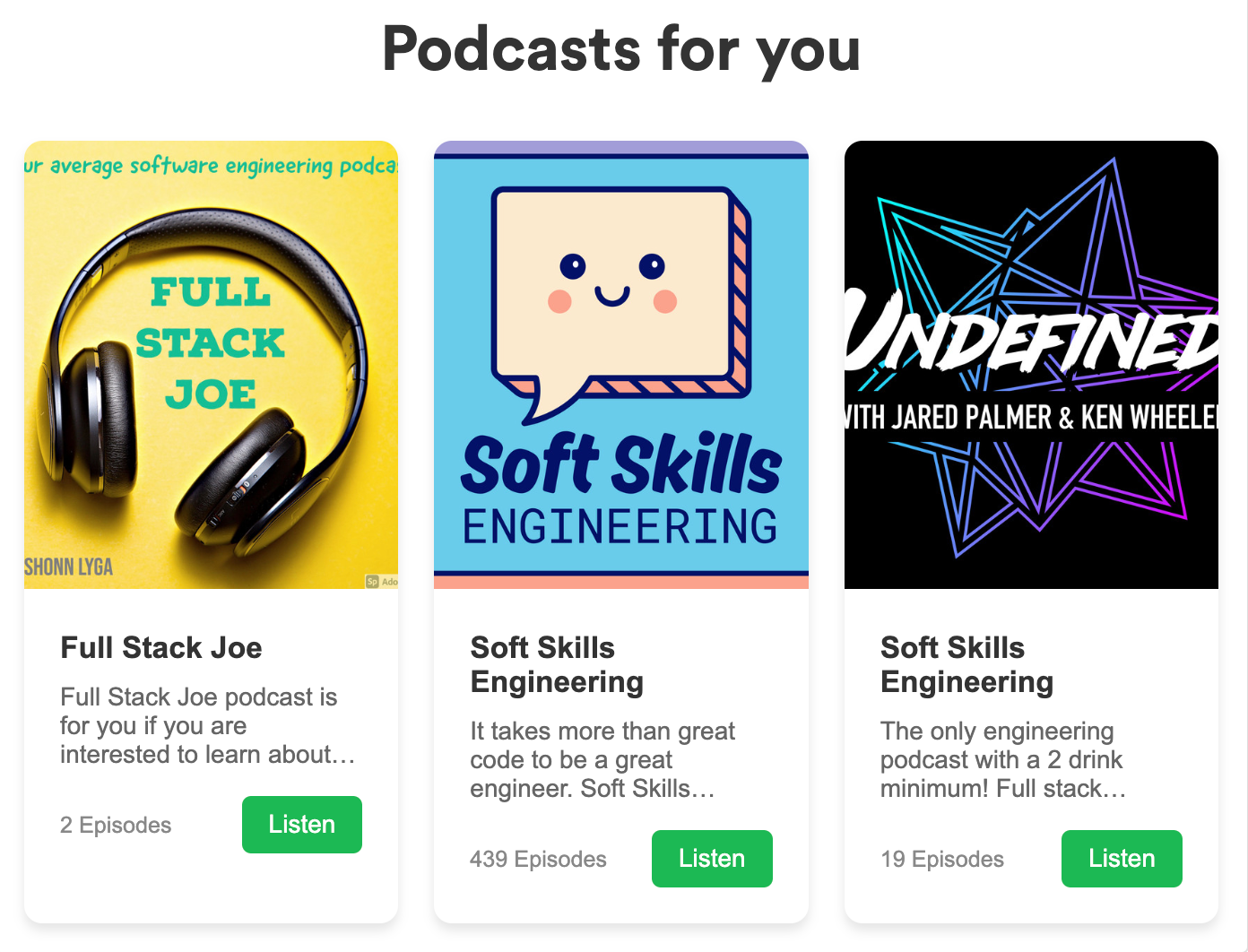
For some extra pizzaz, we’ve generated a fake linkedIn post and hit the Spotify API to showcase three podcasts the resume-holder might listen to.
Extra consideration: reCaptcha & rate limiting
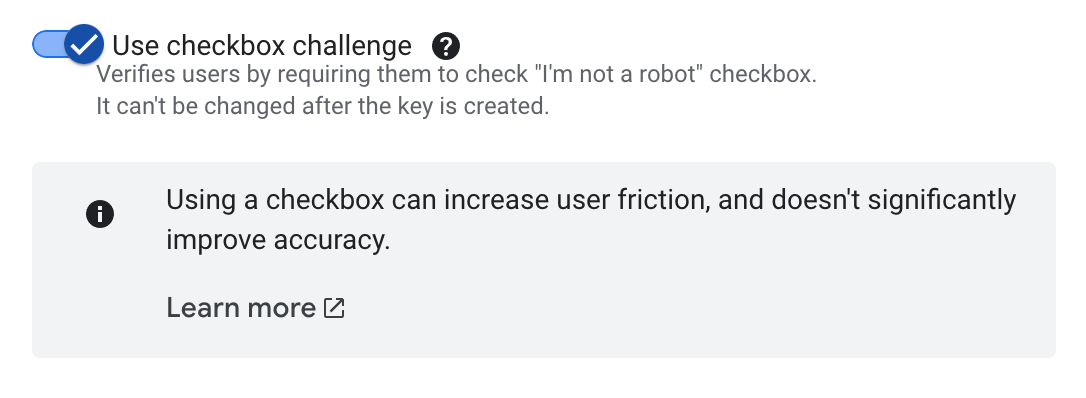
While this operation is simple, it does include a file upload and a paid API call. Both of which put me at risk to a certain extent. Requiring reCaptcha is a drop in the ocean for someone with malicious intent, but probably worth it for the every-day spambot (I don’t have a huge amount of knowledge in the space of automated bad actors).
Something I didn’t realise when setting up reCaptcha is a passive captcha is almost as accurate as the checkbox.
Nginx has a brilliantly documented article on rate limiting too, which was helpful.
See it in action
https://resume.trentbowden.dev/
What’s next
Filetypes are fun and chaotic to explore. Recently, I’ve done some looking into the HEIC image format. It’s a high efficiency image format Apple uses reguarly, but it’s a closed patent format that ‘may’ require a license, which poses a real interesting question of how to handle them from mobile-upload-enabled applications.
—
Extra reading:
PDF Scripting coordinate systems & info
One Font Vulnerability To Rule Them All: Google Project Zero